Wie können wir die Effektivität fortschrittlicher KI-Systeme, sogenannter Foundation-Modelle, steigern, indem wir ihren Zugang zu Kontextinformationen verbessern? Um dieser Frage nachzugehen, haben wir Retrieval-Augmented Generation (RAG) untersucht – eine Methode, die es diesen Modellen ermöglicht, relevante Informationen aus externen Quellen abzurufen, was zu genaueren und aussagekräftigeren Antworten führt. Unter Einsatz von RAG in Datenräumen entsteht eine Architektur, die einen dezentralen Datenaustausch zwischen verschiedenen Teilnehmenden ermöglicht, der Datenschutz und Eigentumsrechte berücksichtigt.

Die Architektur: Kontextdaten aus dezentralen Netzwerken
Um die Herausforderung zu bewältigen, Foundation-Modelle durch einen besseren Zugang zu Kontextdaten zu verbessern und gleichzeitig die Datenhoheit zu wahren, haben wir eine innovative Architektur entwickelt, die Retrieval-Augmented Generation (RAG) mit dem Konzept der Datenräume kombiniert. Dieser Ansatz ermöglicht es großen Sprachmodellen (Large Language Models, kurz LLMs), Kontextdaten nicht nur aus lokalen Datenbanken, sondern auch von anderen Teilnehmenden in einem dezentralen Netzwerk abzurufen. Das bedeutet, dass wir den Datenaustausch nicht nur innerhalb eines Unternehmens, sondern auch zwischen verschiedenen Organisationen erleichtern können, wodurch die für LLMs verfügbaren Informationen erweitert werden und diese genauere und relevantere Antworten generieren können.
Unsere Architektur basiert auf einem praktischen Beispiel aus der realen Welt: einem Netzwerk von Universitäten, die ihre Forschungsarbeiten austauschen. Diese Konfiguration bietet Studierenden und Lehrenden einen einfachen Zugang zu Informationen, ohne dass sie unzählige Dokumente manuell durchsehen müssen. Wir haben eine chatbasierte Benutzeroberfläche entwickelt, die die Interaktion mit dem LLM vereinfacht. Benutzer können ihre Anfragen einfach über diese Schnittstelle einreichen. Sie haben drei Optionen zur Auswahl: Sie können sich auf das integrierte Wissen des LLM verlassen, auf ihren lokalen Kontext zurückgreifen (der alle Arbeiten umfasst, die sie ihrer Datenbank hinzugefügt haben) oder Kontext aus Arbeiten beziehen, die im Datenraum verfügbar sind. Diese Flexibilität ermöglicht es Benutzern, Ergebnisse zu vergleichen und zu entscheiden, welche Informationsquellen sie für ihre Antworten verwenden möchten. Um die Sicherheit zu gewährleisten und die Eigentumsrechte an den Daten zu respektieren, implementieren wir außerdem die inhärenten Richtlinien des Eclipse Dataspace Connector (EDC), auf die wir später noch näher eingehen werden.
User-Workflow
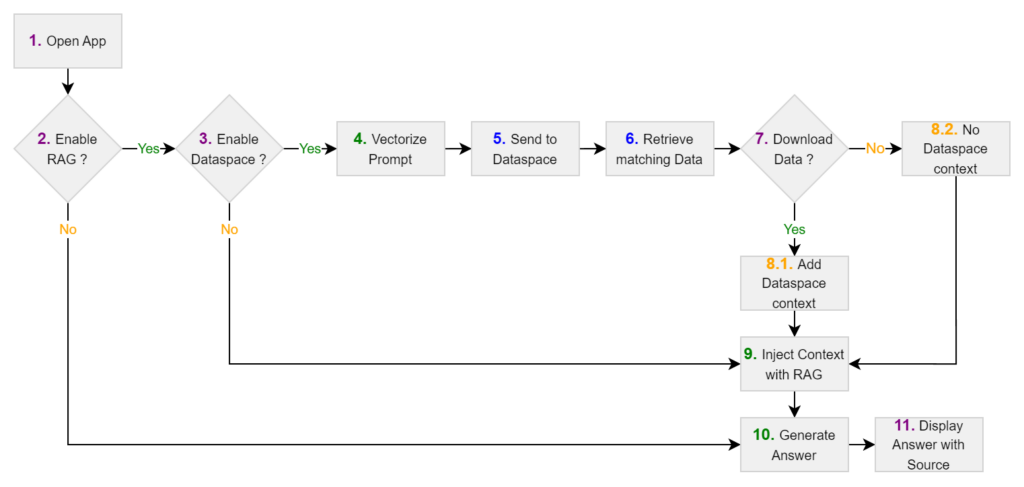
Abbildung: Flussdiagramm des Data Space RAG
Als wir mit der Entwicklung unserer LLM-Anwendung mit Chat-Schnittstelle begannen, war uns bewusst, dass Benutzererfahrung und Benutzerfreundlichkeit entscheidend sind. Unser Ziel war es, die Anwendung benutzerfreundlich zu gestalten und den Benutzenden die Kontrolle darüber zu geben, auf welche Quellen sie sich für ihre Antworten stützen möchten. Um dies zu erreichen, haben wir einen einfachen Benutzerablauf entwickelt. Die Benutzenden haben die Möglichkeit, RAG ein- oder auszuschalten, was in erster Linie dem Vergleich und der Bewertung der Qualität der generierten Antworten dient. Diese Flexibilität ermöglicht es uns, Aussagen über die Leistungsfähigkeit unserer Anwendung zu treffen. Wir wollten den Benutzenden auch die Wahl lassen, ob sie RAG mit allen verfügbaren Kontexten verwenden möchten, wobei sowohl lokale Datenbanken als auch der Datenspeicher herangezogen werden, oder ob sie sich nur auf ihren lokalen Kontext beschränken möchten, der alle ihnen zur Verfügung stehenden Dokumente umfasst. Das bedeutet, dass es drei verschiedene Möglichkeiten gibt, Antworten für jede Anfrage zu generieren:
- LLM
- LLM + lokaler RAG
- LLM + Datenspeicher-RAG
Wir möchten zeigen, wie unsere Anwendung in Kombination mit der Nutzung von Dataspaces die Qualität der generierten Antworten verbessern kann. Ein weiterer großer Vorteil dieser Konfiguration besteht darin, dass die Benutzenden kontrollieren können, welche Daten sie einbeziehen oder ausschließen möchten, und dass sie genau wissen, woher die vom LLM verwendeten Informationen stammen. Wenn Benutzende die Data Space-Option aktivieren, sucht unsere Anwendung nach verfügbaren Forschungsarbeiten und präsentiert sie ihnen. Jede Arbeit erhält eine Relevanzbewertung, die darauf basiert, wie gut sie mit der Anfrage übereinstimmt. Diese Bewertung wird während des RAG-Prozesses unter Verwendung semantischer Näherungsmaße in der Vektordatenbank berechnet.
Damit eine Arbeit im RAG-Prozess verwendet werden kann, muss sie zunächst übertragen werden, und der Benutzer muss den zugehörigen Richtlinien zustimmen. Diese Richtlinien können einmalige Zahlungen, Abonnementgebühren oder Bedingungen wie Zeitlimits oder Nutzungsbeschränkungen umfassen. Nach erfolgreicher Übertragung werden die Informationen des Artikels als extern klassifiziert und für die Verwendung durch RAG verfügbar gemacht, sofern die Datenspeicheroption aktiviert ist. Wenn der Benutzende den Richtlinien nicht zustimmt, wird der Prozess nicht fortgesetzt, und wenn die Übertragung fehlschlägt, muss er von vorne beginnen.
Komponenten der Architektur
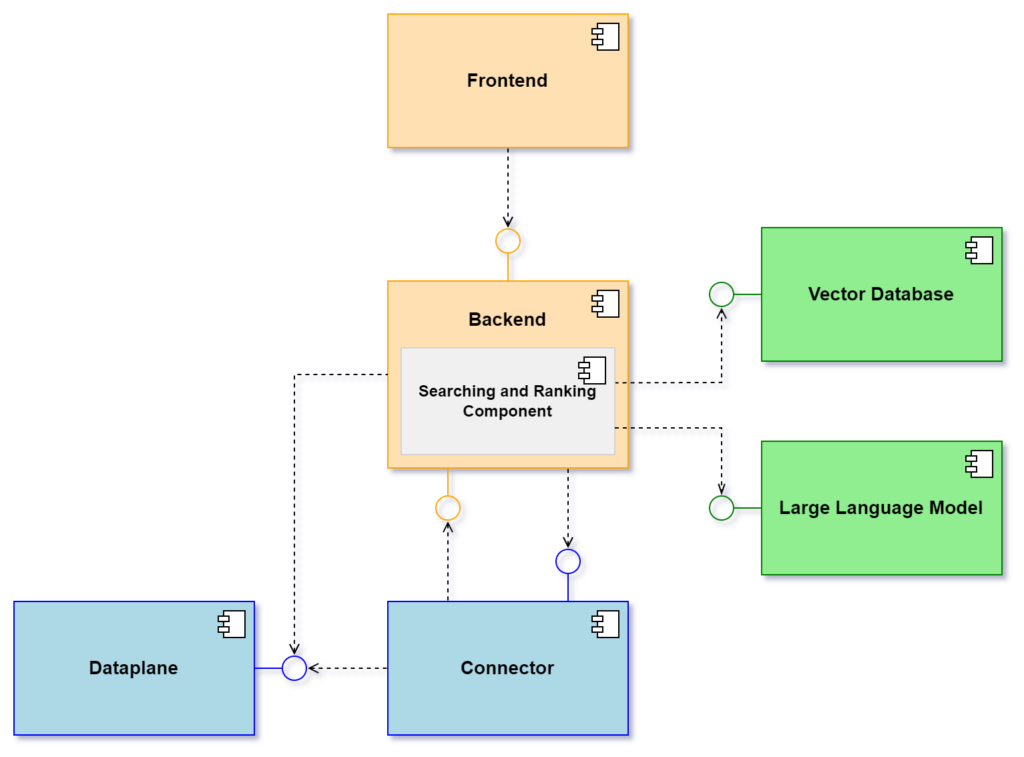
Abbildung: Architektur des Dataspace RAG
Architektur des Dataspace RAG
In diesem Abschnitt werden wir die Komponenten unserer Architektur und deren Zusammenspiel näher erläutern. Unser System basiert auf vier Schlüsselkomponenten:
- Frontend: Dies ist die Chat-Oberfläche, über die Benutzende mit dem System interagieren, Anfragen stellen, Antworten anzeigen und ihre Einstellungen verwalten können.
- Backend: Dieser Teil übernimmt die Logik für die RAG-Pipeline und ermöglicht die Kommunikation zwischen dem Frontend und dem Connector.
- Konnektor: Wir verwenden den Eclipse Dataspace Connector, der Datenressourcen verwaltet und über definierte Richtlinien für deren sichere Bereitstellung sorgt. Die Data Plane des EDC greift dabei direkt auf den angebundenen Object-Storage-Dienst (OBS) zu und führt die eigentliche Datenübertragung durch.
- Großes Sprachmodell: Zur Generierung von Antworten verwenden wir Llama 3.3 7b und speichern Kontextdaten in einem vektorisierten Format in der Vektordatenbank ChromaDB.
Um unser dezentrales Retrieval-Augmented-Generation-Framework optimal nutzen zu können, muss jeder Teilnehmende über diese Komponenten verfügen. Dies bedeutet, dass es kein zentrales Repository für die Kontextspeicherung gibt, sodass wir die Datenhoheit bewahren und gleichzeitig Richtlinien für die Datenübertragung durchsetzen können.
Das Frontend fungiert wie ein Chatbot, über den Benutzende Anfragen stellen und innerhalb des Data Spaces nach zusätzlichen Informationen suchen können. Das Backend verwaltet die Geschäftslogik und sorgt für eine reibungslose Kommunikation zwischen der Benutzeroberfläche und den Datenverwaltungssystemen. Der Connector wickelt alle Interaktionen mit anderen Datenspeicherteilnehmenden ab, einschließlich der Datenübertragungen und der Durchsetzung von Richtlinien. Wenn Dokumente zur Dataplane hinzugefügt werden, werden sie vektorisiert und in der Vektordatenbank gespeichert. Wenn ein Dokument aufgrund des Ablaufs einer Richtlinie entfernt wird, wird es auch aus der Vektordatenbank gelöscht, sodass nur relevanter Kontext für den RAG-Prozess verfügbar ist. Dieser Ansatz ermöglicht es uns, Richtlinien mit zeitlichen oder nutzungsbezogenen Beschränkungen umzusetzen.
Komponenten-Workflows: Wie arbeitet man mit dem Tool?
In diesem Abschnitt erläutern wir die verschiedenen Workflows, die bei unserer Implementierung zum Einsatz kommen. Wenn wir von einem »Asset« sprechen, meinen wir eine Sammlung von Metadaten, die einen Datensatz beschreiben, beispielsweise eine Forschungsarbeit. Die Begriffe »Consumer« und »Provider« bezeichnen die Partei, die das Asset anfordert, bzw. die Partei, die es bereitstellt. Beginnen wir mit dem Workflow für das Hochladen einer Arbeit in die Dataplane:
Hochladen einer Arbeit

Abbildung: Workflow of Paper Upload
Workflow des Dokumenten Uploads
Der erste Schritt besteht darin, ein Dokument in die Dataplane hochzuladen. Danach müssen wir das Asset im Konnektor registrieren. Der Konnektor verwendet Metadaten, um die hochgeladene Datei direkt mit dem Asset zu verknüpfen. Sobald dies geschehen ist, benachrichtigt er das Backend, das das Dokument aus der Dataplane abruft. Das Dokument wird dann vektorisiert und in der Vektordatenbank gespeichert. Nach Abschluss dieses Vorgangs informiert das Backend den Konnektor, der wiederum den Benutzenden benachrichtigt. Das Löschen eines Dokuments erfolgt nach einem ähnlichen Verfahren: Anstatt ein neues Asset zu erstellen, wird das vorhandene gelöscht, wodurch auch die entsprechenden Daten aus der Vektordatenbank entfernt werden.
Dokument suchen

Abbildung: Relevante Assets im Dataspace finden
Relevante Assets im Data Space finden
Als Nächstes untersuchen wir, wie relevante Daten über den Datenraum identifiziert werden können. In diesem Beispiel fungiert ein Forschungsinstitut als Consumer, während der Konnektor einer Universität als Provider dient. Der Arbeitsablauf beginnt, wenn der Consumer eine Anfrage stellt, die an das Backend gesendet wird. Das Backend ruft dann die API des Konnektors auf, um Daten von den Teilnehmenden im Datenraum anzufordern – ein Vorgang, der als Katalogabfrage bezeichnet wird. Diese Anfrage enthält die Frage des Benutzenden. Der Konnektor des Providers empfängt die Anfrage, die enthaltene Frage wird vektorisiert und eine Ähnlichkeitssuche in der Vektordatenbank durchgeführt und die Ergebnissen in form von Aseets basierend auf dessen Relevanz geordnet. Die Ähnlichkeitswerte werden den Metadaten jedes Assets hinzugefügt, die dann zur Verarbeitung und Anzeige in der Benutzeroberfläche an das Backend des Consumers zurückgesendet werden.
Anforderung eines relevanten Dokuments

Abbildung: Anforderung von Assets im Dataspace
Anforderung von Assets im Data Space
Abschließend beschreiben wir den Arbeitsablauf für die Anforderung eines Dokuments aus dem Datenspeicher und dessen Einbindung in den lokalen Kontext des Consumers zur Verwendung im Retrieval-Augmented-Generation-System. Der Prozess beginnt, wenn ein Benutzender ein Dokument über die Benutzeroberfläche auswählt. Es erscheint ein Bestätigungsdialog, in dem der Benutzende die zugehörigen Richtlinien akzeptieren oder ablehnen kann, bei denen es sich um einen Vertrag, ein Abonnement oder eine einmalige Zahlung handeln kann. Wenn der Benutzende zustimmt, ruft das Backend die API des Konnektors auf, um das Dokument beim Provider anzufordern, wodurch eine Vertragsverhandlung eingeleitet wird.
Wenn der Benutzende die Richtlinien ablehnt, endet der Prozess an dieser Stelle. Wenn die Verhandlung erfolgreich ist, fordert der Konnektor des Consumers die Übertragung der Daten an. Sobald die Übertragung abgeschlossen ist, löst das Backend die Vektorisierung des Dokuments aus, wobei dieselbe Methode wie beim Upload-Prozess angewendet wird. Danach wird das Frontend benachrichtigt und das Dokument aus der Liste der verfügbaren externen Quellen im Datenspeicher entfernt. Dadurch kann die Retrieval-Augmented-Generation-Pipeline auf die neu integrierten Kontextdaten zugreifen und die LLM-Antworten verbessern.
Zukünftige Verbesserungen
Datenübertragung
Wenn wir derzeit Informationen aus dem Datenraum für den Retrieval-Augmented-Generation-Prozess anfordern, wird das gesamte Dokument im PDF-Format an den Consumer übertragen, wodurch dieser vollen Zugriff auf das Dokument erhält. Diese Methode funktioniert zwar gut im Rahmen unserer etablierten Richtlinien zur Verhinderung unbefugter Zugriffe, aber es gibt noch Verbesserungspotenzial. Anstatt das gesamte Dokument zu versenden, könnten wir die Effizienz steigern, indem wir nur die spezifischen Datensegmente übertragen, die vom RAG während seiner Ähnlichkeitssuche identifiziert wurden. Dies würde es den Providern ermöglichen, eine bessere Kontrolle über die Vertraulichkeit ihrer gesamten Datenbestände zu behalten.
Fortgeschrittene RAG-Techniken
Unser aktuelles Design verwendet eine Basis-RAG-Architektur, die sich in erster Linie auf die Integration mit Datenräumen konzentriert. Die Basis-RAG-Pipeline führt eine Ähnlichkeitssuche unter Verwendung eines vektorisierten Prompts in der Vektordatenbank durch und gibt die semantisch ähnlichsten Datensegmente zurück. Es gibt viele mögliche Verbesserungen, die wir am RAG-Prozess vornehmen können, von der Verbesserung der Abfrageverarbeitung bis zur Verfeinerung des Abrufmechanismus. Zukünftige Forschung wird sich mit der Integration fortgeschrittener Techniken in die modifizierte RAG-Pipeline befassen, darunter Intent-detection, Re-ranking and Re-packing.
Weiterführende Infos:
Video »Let your knowledge grow – Evaluate protected data with LLMs«
Referenzen
- Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.-t., Rocktäschel, T., et al. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Information Processing Systems, 33, 9459–9474.
- Addison, P., Nguyen, M.-T. H., Medan, T., Shah, J., Manzari, M. T., McElrone, B., Lalwani, L., More, A., Sharma, S., Roth, H., Yang, I., Chen, C., Xu, D., Cheng, Y., Feng, A., & Xu, Z. (2024). C-FedRAG: A Confidential Federated Retrieval-Augmented Generation System. arXiv, abs/2412.13163. Retrieved from https://api.semanticscholar.org/CorpusID:274789195
- Guerraoui, R., Kermarrec, A.-M., Petrescu, D., Pires, R., Randl, M., & de Vos, M. (2025). Efficient Federated Search for Retrieval-Augmented Generation. In Proceedings of the 5th Workshop on Machine Learning and Systems (pp. 74–81). Association for Computing Machinery. https://doi.org/10.1145/3721146.3721942
- Jiang, E., Chen, A., Tenison, I., & Kagal, L. (2024). MediRAG: Secure Question Answering for Healthcare Data. In 2024 IEEE International Conference on Big Data (BigData) (pp. 6476–6485). https://doi.org/10.1109/BigData62323.2024.10825604
- Koga, T., Wu, R., & Chaudhuri, K. (2024). Privacy-Preserving Retrieval Augmented Generation with Differential Privacy. arXiv preprint, abs/2412.04697. Retrieved from https://api.semanticscholar.org/CorpusID:274581388
- Zhao, D. (2024). FRAG: Toward Federated Vector Database Management for Collaborative and Secure Retrieval-Augmented Generation. arXiv preprint, abs/2410.13272. Retrieved from https://api.semanticscholar.org/CorpusID:273404015
- Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., Dai, Y., Sun, J., Wang, H., & Wang, H. (2023). Retrieval-augmented generation for large language models: A survey. arXiv preprint, arXiv:2312.10997
- Otto, B., Ten Hompel, M., & Wrobel, S. (2022). Designing data spaces: The ecosystem approach to competitive advantage. Springer Nature.
- Hermsen, F., Nitz, L., Akbari Gurabi, M., Matzutt, R., & Mandal, A. (2024). On Data Spaces for Retrieval Augmented Generation. In INFORMATIK 2024 (pp. 701–707). Gesellschaft für Informatik eV.
- Cuconasu, F., Trappolini, G., Siciliano, F., Filice, S., Campagnano, C., Maarek, Y., Tonellotto, N., & Silvestri, F. (2024). The power of noise: Redefining retrieval for RAG systems. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (pp. 719–729).
- Wang, X., Wang, Z., Gao, X., Zhang, F., Wu, Y., Xu, Z., Shi, T., Wang, Z., Li, S., Qian, Q., Yin, R., Lv, C., Zheng, X., & Huang, X. (2024). Searching for Best Practices in Retrieval-Augmented Generation. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (pp. 17716–17736).
- Han, B., Susnjak, T., & Mathrani, A. (2024). Automating Systematic Literature Reviews with Retrieval-Augmented Generation: A Comprehensive Overview. Applied Sciences, 14(19), 9103.
- IEEE/ISO/IEC International Standard for Software, systems and enterprise–Architecture description, in ISO/IEC/IEEE 42010:2022(E) , vol., no., pp.1-74, 7 Nov. 2022, doi: 10.1109/IEEESTD.2022.9938446. keywords: {IEEE Standards;ISO Standards;IEC Standards;Software engineering;System analysis and design;Software architecture},
Neueste Kommentare
Neueste Beiträge
- Green IT: Ressourceneffiziente Cloud- und Datenwirtschaft in Deutschland
- Green IT und KI — Künstliche Intelligenz als Freund oder Feind der Nachhaltigkeit?
- Let your knowledge grow: Wie Retrieval-Augmented Generation und Large Language Models in Datenräumen den organisationsübergreifenden Wissensaustausch verbessern
Schreibe einen Kommentar